In before you tell me, React dev be like after hearing about object oriented design pitch.
Just to start, I think this attitude is reasonable after our collective foot gun trauma with earlier React class component. If anybody remember the good old day of 2015 to early 2019, you’d remember the nonsense behind super nuances, lambda method interaction with the this keyword in JS and the need of .bind. Not to mention how incredibly bloated the code looks like. I think this article summed the problem up pretty well. Yuck indeed.
It’s without a shadow of doubt that the functional API with hooks are better on every front, so we can safely conclude that object oriented design is obsolete as an idea for user interface development using React, right?
Well, hold on. Not so fast. I think this paradigm has some useful ideas that can be used to solve very specific problems, and this article is my attempt to convince you that OOP, in a form of a wrapper class can help your code more organized, testable, and provide better ergonomics by unlocking access to well-known design patterns.
If you work on the type of application that offset as much of these complicate logic about state to your backend (aka just slaps on tanstack query and profits), then this pitch isn’t applicable to you. If you are one of those unfortunate (😅) devs who work on a behemoth of a SPA, and there’s a lot of complicated data work that needs to be performed on the client like me, then this article is for you.
Why, just why?
Status Quo: Utility-first approach
My current day job is the CRM system at HubSpot, specifically the Index Page. As you’d figure, making a world-class CRM is no easy business, and the amount of logic to that business in my team’s codebase is staggering. In fact, it’s probably the largest codebase in the entirety of HubSpot, often giving our internal typescript language server a run for its money, and it takes 20 minutes to build in the CI pipeline, but I digress.
Within the CRM, customer data are organized around Objects. We have a growing collections of standardly defined Objects like Contacts, Deals, Companies, Tasks, etc. and users can define their own Custom Objects. Each Object has a list of properties, where the actual data corresponds to. For example, a user using Contact object to track their customers interactions may have properties like first_name, last_name and email, amongst other things.
One of the core value proposition of my team, the Index Page, is the data table. The table typically display property value, like a database. However, instead of displaying the underlying unique ID of each Object instance (called record), some sort of a primary display label is shown. For instance:
Company type: company name.
Deal type: deal name.
Ticket: ticket name.
Contact: full name, falling back to email.
For most object, the property that specify display label is decided by the backend. For the vast majority of Object types out there, getting a primary display label is run-off-the-mill.
However, there are special cases, such as the Contact object. We’d try to display a full name instead from the first name and last name, falling back to email if possible.
In pseudo code (not our actual production code), you can imagine something like this.
// filename: PrimaryDisplayLabelCell.tsxconst getDisplayLabel( metaData: ObjectMetaData, record: ObjectRecord): string | undeined { // special case. if (objectMeta.type === 'CONTACT') { // first name and last name may be undefined, need to fallback to email return [record.first_name, record.last_name].join(" ").trim() || record.email; } if (objectMeta.primaryDisplayLabel) { return record[objectMeta.primaryDisplayLabel] } // failed to get primary display label at this point.}function PrimaryDisplayLabel({ meta, record }: PrimaryDisplayLabelCellType) { const primaryDisplayLabel = getDisplayLabel(meta, record); // still need to handle undefined case return <>{primaryDisplayLabel}</>}
We’d define a “utility” function in the same file where the component is defined. The function will handle the Contact object special case for us. This is a typical approach to solve this problem in React.
Since getting primary display label can result in undefined (i.e., fail), we need to have another level of fallback. For the data table, we fallback to the record creation timestamp.
function PrimaryDisplayLabel({ meta, record }: PrimaryDisplayLabelCellType) { const primaryDisplayLabel = getDisplayLabel(meta, record);+ const fallback = getCreateAtTime(meta, record); - // still need to handle undefined case- return <>{primaryDisplayLabel}</>+ return <>{primaryDisplayLabel ?? fallback}}
Let’s call this strategy a utility-first approach.
Utility-first approach
Share common features such as data derivation by creating utility functions in helper files.
Poor discoverability and Implementation drift
The actual HubSpot system have other features like Association. These needs to have primary display label logic too. Not only is there a completely different data type besides core Object that exhibit this feature, getting primary display label is of the business of other UI areas, such as the Record page where users can dive deeper into the details of a particular record.
Since this primary display label is not a data that you can directly get from the backend, and Association is a different feature that may shows up in different components, we’ve made attempts to extract this logic to a commonly shared module. As you could have guess, it lives in a utility.
// util.ts - or some other similarly name file/directoryexport const getDisplayLabel(metaData: ObjectMetaData | AssociationMetaData, record: ObjectRecord | AssociationRecord) { if ('associationId' in metaData) { // duck-type checking that it's association /* Association version */ else { /* core Object version */ } } }
The problem with utility-first approach is when you have such a huge codebase like my teams’, with mid-migration code, your newly onboard devs simply aren’t aware of all the scattered utilities as they work on a separate systems / parts of the system.
Drawback 1: Poor discoverability
Utility-first approach suffers from poor discoverability when the codebase reach a certain critical mass.
In reality, I’ve seen this separate system that shares the same behavior have a different implementation that doesn’t match all of our PM’s requirement, leading to some differences. Let’s call this implementation drift.
Drawback 2: Implementation drift
When two system that should exhibit the same behavior, but are instead implemented independently, often with differing or contradictory behaviors.
Less unit-testability
The component I shared above is a sane-washed version for the sake of example. In our actual production system at HubSpot, we relies on Context quite heavily. The actual component that renders the display label often retries object meta data and record data directly from context and/or fetching from GraphQL. With the philosophy of asserting only the rendering outcome from RTL, the cost of writing tests scales as we have to provide mocking and stubbing network calls with msw.
With test setup being a high cost activity, it becomes more expensive to write and run tests that asserts all nuances of getting the primary display label right, amongst other concerns. If the logic is implemented locally in the component, in a useMemo hook for example, then it is prohibitively unergonomic to thoroughly test this feature, which can lead to bugs and regressions.
Drawback 3: Co-locating utility function to component complicates testing
Directly writing utility within the component (such as a useMemo block) complicates testing all behavior of the utility, often resulting sub-par test coverage.
What’s your suggestion, then?
The way I see it, in the story I shared above, there are data (core Object, Association), and methods that operates on those data (getPrimaryDisplayLabel, getCreationTimeStamp). Since we have a problem of Poor discoverability and Implementation drift, why not co-locate the those two together for better locality of behavior?
Object-oriented programming has its vices (diamond problem) and problematic dogmas (looking a you, Java, with your one-method class nonsense). But credit is due when its due: OOP has some very good perks:
Tooling support to discover methods so you don’t have to go into rummage the utils file to look for the right functions.
Private fields and methods (encapsulation) to lower your onboarding team members exposure to cognitive overhead.
Pitch: Use wrapper utility class
As I said, OOP has its pitfall. It takes a specific strategy to get all the benefits above without the trap of over-sharing.
What we can do to solve this problem is creating a wrapper utility class whose inner POJO (plain javascript object) is public.
class ObjectMetaDataWrapper { // inner is a plain javascrip object, and it is publicly readable. constructor(readonly public inner: ObjectMetaData) {}; tryGetDisplayLabel(this: ObjectMetaDataWrapper): string | undefined { /** implementation */ }}
Front-end application typically gets the data from our network. The very first constrains we can run into is around serialization/deserialization. This is a complex problem with lots of pitfalls, so it’s best to avoid it altogether. By wrapping over server-side response (which are POJO) and having it public, we can simply work on serializing / deserializing the inner object instead, bypassing the complexity.
Stick to POJO to avoid serialization/deserialization pitfalls.
Let’s absolutely Not replace plain javascript object (POJO) with data model class to avoid accidental complexity around serialization / deserialization.
Secondly, there are many one-off data process that is bespoken to a UI Component. We definitely do not want to close these door by over-engineering our encapsulation.
inner POJO should be public readonly
Keep inner POJO public for ad-hoc data work in Components. To control against accidental mutation, declare inner POJO as readonly.
I think this design provides the best of both world:
No getters/setters nonsense like in Java.
Readonly to suggest immutable update only.
No serialization/deserialization issue. Inner POJO can be jsonified like usual.
Ad-hoc data transformation allowed.
Opens door for OOP style pattern.
Also, since this design focus on providing utility and co-locating methods with data rather than modeling the domain entity (which is often Back End’s responsibility), these class are not meant to be subclassed (so no inheritance issue.)
Do not subclass
Utility wrapper class should not be subclassed to avoid issue around inheritance.
For mutation
So far, the example I’ve shown has been about derived data only. There’s the other side of the coin, which is mutation.
The core principle behind a lot of the “state management” pattern we see nowadays in React ecosystem has its root in functional programming paradigm, where we prefer immutable data for referential transparency.
We can updates our wrapper class pattern updating methods to make the update immutable instead, satisfying the principle of Functional Programming. For example, consider how we may implement some complicated mutation logic, such as “mark this contact as marketable” with familiar tool like Immer.
class ContactObjectWrapper { constructor(public readonly inner: ObjectData) {}; tryMarkAsMarketable(this: ContactObjectWrapper): ContactObjectWrapper { return new ContactObjectWrapper( produce(draft => { draft.properties['marketable'] = true; // other updating rules for keeping invariants }) ) }}
At the same time, preserving the ergonomics of ad-hoc mutation. Plus, we have an added protection by the readonly declaration.
// in componentconst objectData = useObjectData();const contactObjectWrapper = new ContactObjectWrapper(objectData);const changeEmail = useCallback((newEmail: string) => { // adhoc mutation allowed because the wrapper inner POJO is public. const newWrapper = new ContactObjectWrapper( {...contactObjectWrapper.inner, email: newEmail} )});
Mutation methods should be pure and update immutably
This design makes it possible and natural to use this wrapper class pattern for state management and adheres to Function Programming principle, which results important benefits.
Benefits
Tooling autosuggest for better discoverability
The vast majority of IDE out there, especially VSCode supports some form of autosuggestion.
Here we have an toy implementation of the idea. When the class instance metaDataWrapper is access, intellisense autosuggests our methods. There’s no need to go find and trace that utility files! This is a pretty big DX win in my opinion.
To be honest, I think the series of if/else like the earlier example above can be quite exhausting to look at and work with, as duck-typing aren’t very reliable.
// filename: PrimaryDisplayLabelCell.tsxconst getDisplayLabel( metaData: ObjectMetaData, record: ObjectRecord): string | undeined { // special case. if (objectMeta.type === 'CONTACT') { // first name and last name may be undefined, need to fallback to email return [record.first_name, record.last_name].join(" ").trim() || record.email; } if (objectMeta.primaryDisplayLabel) { return record[objectMeta.primaryDisplayLabel] } // failed to get primary display label at this point.}function PrimaryDisplayLabel({ meta, record }: PrimaryDisplayLabelCellType) { const primaryDisplayLabel = getDisplayLabel(meta, record); // still need to handle undefined case return <>{primaryDisplayLabel}</>}
The thing about branching conditions is that they lack a design philosophy behind. It’s very easy to add any other conditions that’s not relevant to “selecting type of data”, contaminating your reasonability. For every new data type that shares this behavior, this code will need to grow; if your fellow developer managed to find it in the first place anyway.
We can and should instead express this idea in term of generic. Something like:
If this data type can have display label, then as a component I can render it.
// common interfaceinterface HasPrimaryLabel { tryGetDisplayLabel(): string | undefined}class ObjectMetaDataWrapper implements HasPrimaryLabel { constructor(public inner: { metaData: ObjectMetaData, data: ObjectData }) {}; /** * Attempts to get the primary display label. Handles special case for Contact object type. * * @returns string if successful, undefined if failed. */ tryGetDisplayLabel(this: ObjectMetaDataWrapper): string | undefined { /** implementation */ }}class AssociationMetadataWrapper implements HasPrimaryLabel { constructor(public inner: { metaData: AssociationMetaData, data: AssociationData }) {}; tryGetDisplayLabel(this: AssociationMetadataWrapper): string | undefined { /** implementation */ }}// this component does not need to know whether the data is core Object or Association, or anything else. Anything that can produce display label will work.function PrimaryDisplayLabel({ data }: { data: HasPrimaryLabel }) { return <>{data.tryGetDisplayLabel()}</>}
If we extract this common behavior into interface implementations, then we’d have access to generic implementation (known as Polymorphism). See more: Dynamic dispatch - Wikipedia
Open door to builder pattern for test mocking
At HubSpot, these core Object metadata and Association metadata have invariants that the our current type system can’t represent. For example, we often use feature flags (internally called as gating) to control rollout. These are applied on both the portal (read: customer organization database) and on the specific user (read: person using the software), and the effective feature flag is the overlap of both the portal’s gate and the current user’s gate.
Normally for the system under test, these invariants are ensured by our backend system. However we often see issues in providing mocks in testing. Ensuring invariants in mock is difficult enough for one module, doing so consistently across several codebase is a difficult challenge. For example, I’ve shoot myself in the foot several time by only mocking gate in the user part, forgetting to set the same thing on the portal field.
What the wrapper class pattern unlocks is access to the builder pattern. It’s possible to create a set of setter methods that obeys these invariants, allowing the test code to simulate specific scenarios without exposing the engineer writer to massive cognitive overhead having to learn about these invariants, which often result in shortcuts in test mocking.
Testing and maintaining these components will be simpler (duh!). For our primaryDisplayLabel example earlier, the only dependency is the that HasPrimaryLabel interface, which is a single function rather than an entire object data and metadata. We reduce what needs to be mocked to test the component.
Since there is fewer code, there are less code to test. For the one that does, we can have better focus and coverage.
Wait, are we just complicating things?
Can’t you define functions in POJO as well?
For most purposes they are equivalent, but there’s nuances:
Class methods are defined on the prototype, so they are referentially stable. Deep equality check will yield true. This should not add to any re-render issue, if that’s your concern.
let objectA = new MyObject();let objectB = new MyObject();objectA.method === objectB.method // true
You can use instanceof on class. For object you need duck-typing discriminant field.
Typing is automatic for class, for POJO route you need to provide different typing, which is more boilerplate.
But React best practice is to pass plain object
Have you wonder why there’s .map, .filter on Array and .join, .lowercase on String, even though they look like POJO?
Those methods are defined on their respective prototypes, which is the same mechanism for methods you would define or your own class in Javascript. If you can pass string and array without any issue in props and context, you can pass your own data type without issue as well.
It’s not convention. We don’t do that.
Well, Javascript didn’t have iterator methods like .map() before ES6. Anybody here remember all of the evangelical article on medium circa 2017-2019 discouraging people from explicit for-loop in favor for .forEach() ?
While I do agree that consistency brings value, at some point there’s a tradeoff to be made between a better solution, vs keeping tradition. I think what is presented here are not completely alien. Virtually any engineering degree have course that teaches Object Oriented Programming fundamentals.
Technology is in the business of innovation. Traditionalist arguments are to be taken with a heathy dose of skepticism.
Conclusion
Drawing my experience at HubSpot, chances are a large enough React codebase will experience the weight of its complexity. Shared logic, given the current status quote approach of the community, which is the Utility-first approach, may lead to poor discoverability, which leads to implementation drift and handicaps effective and thorough testing. I think there’s lesson to be learnt from a sensible and limited adoption of object oriented design.
When used in a form of a wrapper that cannot be subclassed, while still allowing public access to the inner data structure, this patterns address the discoverability and implementation drift issue. It furthers open doors to polymorphic code, fluent style API and other power tools against complexity. The benefits and design space this tool opens are really attractive, and I think it pays dividends for teams to be pragmatic and consider all the options on the table.



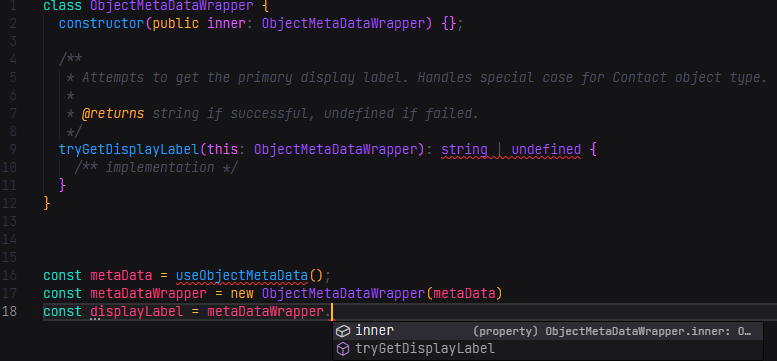 Here we have an toy implementation of the idea. When the class instance
Here we have an toy implementation of the idea. When the class instance 

